Bottom-up parsing
In computer science, parsing reveals the grammatical structure of linear input text, as a first step in working out its meaning. Bottom-up parsing identifies and processes the text's lowest-level small details first, before its mid-level structures, and leaving the highest-level overall structure to last.
Bottom-up Versus Top-down
The bottom-up name comes from the concept of a parse tree, in which the most detailed parts are at the bottom of the (upside-down) tree, and larger structures composed from them are in successively higher layers, until at the top or "root" of the tree a single unit describes the entire input stream. A bottom-up parse discovers and processes that tree starting from the bottom left end, and incrementally works its way upwards and rightwards.[1] A parser may act on the structure hierarchy's low, mid, and highest levels without ever creating an actual data tree; the tree is then merely implicit in the parser's actions. Bottom-up parsing lazily waits until it has scanned and parsed all parts of some construct before committing to what the combined construct is.
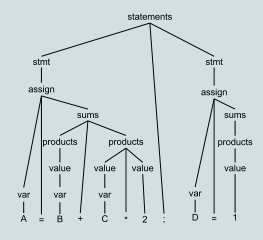 Typical parse tree for A = B + C*2; D = 1 |
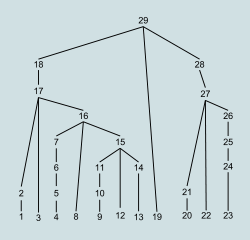 Bottom-up parse steps |
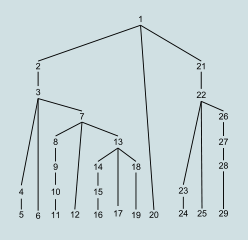 Top-down parse steps |
The opposite of this are top-down parsing methods, in which the input's overall structure is decided (or guessed at) first, before dealing with mid-level parts, leaving the lowest-level small details to last. A top-down parser discovers and processes the hierarchical tree starting from the top, and incrementally works its way downwards and rightwards. Top-down parsing eagerly decides what a construct is much earlier, when it has only scanned the leftmost symbol of that construct and has not yet parsed any of its parts. Left corner parsing is a hybrid method which works bottom-up along the left edges of each subtree, and top-down on the rest of the parse tree.
If a language grammar has multiple rules that may start with the same leftmost symbols but have different endings, then that grammar can be efficiently handled by a deterministic bottom-up parse but cannot be handled top-down without guesswork and backtracking. So bottom-up parsers handle a somewhat larger range of computer language grammars than do deterministic top-down parsers.
Bottom-up parsing is sometimes done by backtracking. But much more commonly, bottom-up parsing is done by a shift-reduce parser such as a LALR parser.
One of the earlier documentations of a bottom-up parser is "A Syntax-Oriented Translator" by Peter Zilahy Ingerman, published in 1966 by Academic Press, NY.
Examples
Some of the parsers that use bottom-up parsing include:
- Precedence parser
- BC (bounded context) parsing
- LR parser (Left-to-right, Rightmost derivation)
- CYK parser
- Recursive ascent parser
- Shift-Reduce Parser
References
- ↑ Compilers: Principles, Techniques, and Tools (2nd Edition), by Alfred Aho, Monica Lam, Ravi Sethi, and Jeffrey Ullman, Prentice Hall 2006.