X-fast trie
| X-fast trie | |
|---|---|
| Type | Trie |
| Invented | 1982 |
| Invented by | Dan Willard |
| Asymptotic complexity in big O notation | |
| Space | O(n log M) |
| Search | O(log log M) |
| Insert | O(log M) amortized |
| Delete | O(log M) amortized |
In computer science, an x-fast trie is a data structure for storing integers from a bounded domain. It supports exact and predecessor or successor queries in time O(log log M), using O(n log M) space, where n is the number of stored values and M is the maximum value in the domain. The structure was proposed by Dan Willard in 1982,[1] along with the more complicated y-fast trie, as a way to improve the space usage of van Emde Boas trees, while retaining the O(log log M) query time.
Structure
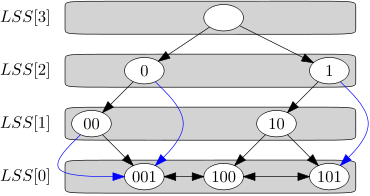
An x-fast trie is a bitwise trie: a binary tree where each subtree stores values whose binary representations start with a common prefix. Each internal node is labeled with the common prefix of the values in its subtree and typically, the left child adds a 0 to the end of the prefix, while the right child adds a 1. The binary representation of an integer between 0 and M − 1 uses ⌈log2 M⌉ bits, so the height of the trie is O(log M).
All values in the x-fast trie are stored at the leaves. Internal nodes are stored only if they have leaves in their subtree. If an internal node would have no left child, it stores a pointer to the smallest leaf in its right subtree instead, called a descendant pointer. Likewise, if it would have no right child, it stores a pointer to the largest leaf in its left subtree. Each leaf stores a pointer to its predecessor and successor, thereby forming a doubly linked list. Finally, there is a hash table for each level that contains all the nodes on that level. Together, these hash tables form the level-search structure (LSS). To guarantee the worst-case query times, these hash tables should use dynamic perfect hashing or cuckoo hashing.
The total space usage is O(n log M), since each element has a root-to-leaf path of length O(log M).
Operations
Like van Emde Boas trees, x-fast tries support the operations of an ordered associative array. This includes the usual associative array operations, along with two more order operations, Successor and Predecessor:
- Find(k): find the value associated with the given key
- Successor(k): find the key/value pair with the smallest key larger than or equal to the given key
- Predecessor(k): find the key/value pair with the largest key less than or equal to the given key
- Insert(k, v): insert the given key/value pair
- Delete(k): remove the key/value pair with the given key
Find
Finding the value associated with a key k that is in the data structure can be done in constant time by looking up k in LSS[0], which is a hash table on all the leaves.[2]
Successor and Predecessor
To find the successor or predecessor of a key k, we first find Ak, the lowest ancestor of k. This is the node in the trie that has the longest common prefix with k. To find Ak, we perform a binary search on the levels. We start at level h/2, where h is the height of the trie. On each level, we query the corresponding hash table in the level-search structure with the prefix of k of the right length. If a node with that prefix does not exist, we know that Ak must be at a higher level and we restrict our search to those. If a node with that prefix does exist, Ak can not be at a higher level, so we restrict our search to the current and lower levels.
Once we find the lowest ancestor of k, we know that it has leaves in one of its subtrees (otherwise it wouldn't be in the trie) and k should be in the other subtree. Therefore the descendant pointer points to the successor or the predecessor of k. Depending on which one we are looking for, we might have to take one step in the linked list to the next or previous leaf.
Since the trie has height O(log M), the binary search for the lowest ancestor takes O(log log M) time. After that, the successor or predecessor can be found in constant time, so the total query time is O(log log M).[1]
Insert
To insert a key-value pair (k, v), we first find the predecessor and successor of k. Then we create a new leaf for k, insert it in the linked list of leaves between the successor and predecessor, and give it a pointer to v. Next, we walk from the root to the new leaf, creating the necessary nodes on the way down, inserting them into the respective hash tables and updating descendant pointers where necessary.
Since we have to walk down the entire height of the trie, this process takes O(log M) time.[3]
Delete
To delete a key k, we find its leaf using the hash table on the leaves. We remove it from the linked list, but remember which were the successor and predecessor. Then we walk from the leaf to the root of the trie, removing all nodes whose subtree only contained k and updating the descendant pointers where necessary. Descendant pointers that used to point to k will now point to either the successor or predecessor of k, depending on which subtree is missing.
Like insertion, this takes O(log M) time, as we have to walk through every level of the trie.[3]
Discussion
Willard introduced x-fast tries largely as an introduction to y-fast tries, which provide the same query time, while using only O(n) space and allowing insertions and deletions in O(log log M) time.[1]
A compression technique similar to patricia tries can be used to significantly reduce the space usage of x-fast tries in practice.[4]
By using an exponential search before the binary search over the levels and by querying not only the current prefix x, but also its successor x + 1, x-fast tries can answer predecessor and successor queries in time O(log log Δ), where Δ is the difference between the query value and its predecessor or successor.[2]
References
- 1 2 3 Willard, Dan E. (1983). "Log-logarithmic worst-case range queries are possible in space Θ(N)". Information Processing Letters. Elsevier. 17 (2): 81–84. doi:10.1016/0020-0190(83)90075-3. ISSN 0020-0190.
- 1 2 Bose, Prosenjit; Douïeb, Karim; Dujmović, Vida; Howat, John; Morin, Pat (2010), Fast Local Searches and Updates in Bounded Universes (PDF), Proceedings of the 22nd Canadian Conference on Computational Geometry (CCCG2010), pp. 261–264
- 1 2 Schulz, André; Christiano, Paul (2010-03-04). "Lecture Notes from Lecture 9 of Advanced Data Structures (Spring '10, 6.851)" (PDF). Retrieved 2011-04-13.
- ↑ Kementsietsidis, Anastasios; Wang, Min (2009), Provenance Query Evaluation: What’s so special about it?, Proceedings of the 18th ACM conference on Information and knowledge management, pp. 681–690