Sloppy identity
In linguistics, sloppy identity is an interpretive issue involved in contexts like verb phrase ellipsis where the identity of the pronoun in an elided VP (verb phrase) is not identical to the antecedent VP.
For example, English allows VPs to be elided, as in example 1). The elided VP can be interpreted in at least two ways, namely as in (1a) or (1b) for this example.
In (1a), the pronoun his refers to John in both the first and the second clause. This is done by assigning the same index to John and to both the “his” pronouns. This is called the “strict identity” reading because the elided VP is interpreted as being identical to the antecedent VP.
In (1b), the pronoun his refers to John in the first clause, but the pronoun his in the second clause refers to Bob. This is done by assigning a different index to the pronoun his in the two clauses. In the first clause, pronoun his is co-indexed with John, in the second clause, pronoun his is co-indexed with Bob. This is called the “sloppy identity” reading because the elided VP is not interpreted as identical to the antecedent VP.

1) John scratched his arm and Bob did too.
This sentence can have a strict reading:
1) a. Johni scratched hisi arm and Bobj [scratched hisi arm] too.
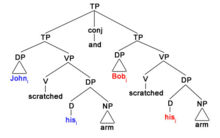
Or a sloppy reading:
1) b. Johni scratched hisi arm and Bobj [scratched hisj arm] too.
History
The discussion of “sloppy identity” amongst linguists dates back to a paper by John Robert Ross in 1967,[1] in which Ross identified the interpretational ambiguity in the elided Verb Phrase of the previously stated sentence 1) found in the intro. Ross tried, without success, to account for “sloppy” identity using strictly syntactic structural relations, and concluded that his theories predicted too many ambiguities.
A linguist named Lawrence Bouton (1970) was the first to develop a syntactic explanation of VP-Deletion,[2] commonly referred to by contemporary linguists as VP – ellipsis. Bouton's theory of VP-Deletion and Ross’ observation of sloppy identity served as an important foundation for linguists to build on.
Many advances followed within the next decade, providing much of the theoretical scaffolding necessary for linguists to address issues of “sloppy identity” up to present day. Most notable of these advances are Lawrence Bouton’s VP-Deletion rule (1970),[2] Barbara Partee’s “Derived-VP rule” (1975),[3] and Ivan Sag’s “Deletion Approach” (1976), based on the Derived-VP rule. It should be noted that theories beyond Ross’s initial discovery have all extended beyond analyses based on observations of structural relations, often using Logical Form and phonetic form to account of instances of sloppy and strict identity. The deletion (derived VP) approach, in combination with the use of Logical Form (LF) and phonetic form (PF) components to syntax, is one of the most widely used syntactic analysis of sloppy identity to date.
Theories
Y model
This model represents the interface level of the phonological system and interpretive system that give us judgements of form and meaning of D-structure. Early theorists seemed to suggest that PF and LF are two distinct approaches for explaining the derivation of VP ellipsis.
Phonetic form approaches
The PF-deletion hypothesis
Scholars like Noam Chomsky (1955),[4] Ross (1969)[5] and Sag (1976)[1] have suggested the process responsible for VP ellipsis is a syntactic deletion rule applied at the level of PF, this process is named as VP Deletion.
The PF-deletion hypothesis assumes the elided VP is fully syntactically represented but deleted in the phonological component between SPELLOUT and PF. It suggests that VP deletion is the process that generates sloppy identities because co-indexation needs to occur with respect to binding conditions.
Example
2.i) John will eat his apple, and Sam will [VPØ] too. 2.ii) [Johni will eat hisi apple] and [Samj will eat hisj apple].
Looking at example 2.i), VP deletion is why a null VP is derived. Before deletion, as seen in example 2.ii), the sentence would in fact be read as “John will eat his apple, and Sam will eat his apple too.” The clauses [John will eat his apple] and [Sam will eat his apple] share an identical VP in the sense they have the same constituent structure, so the second clause can be deleted because it is identical to its antecedent VP.
Now turning to coindexation, this sentence contains two constituents combined by the conjunction “and”. The clauses are each independent complete sentence structures, so presumably each pronoun would co-index to its referent in its constituent to comply with binding theories. With this co-indexation, illustrated in example 2.ii), a sloppy reading is produced.
However, when considering cases sensitive to binding theories, the expected strict reading of sentence 3) would violate the Binding Principle A. According to this principle, an anaphor must be bound in its binding domain, meaning it must be bound within the same clause as its referent.
3) John blamed himself and Bill blamed himself
What you would expect to be the Strict reading
3.i) John i [VP blamed himselfi], and Billj [VP blamed himself i]
What you would expect to be the Sloppy reading
3.ii) Johni [VP blamed himselfi], and Billj [VP blamed himselfj]

Taking this into consideration, it is observed that strict readings are difficult to be obtained in sentences like this, because if the anaphor himself in the elided VP is co-indexed with ‘John’ it would violate Binding Theory A because they are in separate clauses. C-command relationships are represented by colour coding in the sytnax tree. As depicted in the tree diagram and illustrated in green, ‘Johni’ c-commands 'himselfi' in the first VP. 'Billj' on the other hand c-commands 'himselfj' in the second VP, colour coded in orange. Due to binding domains, the DPs closest to the anaphors have be the ones they bind to and co-index with. Therefore, 'Johni' cannot not c-command the 'himselfj' in the second VP, as shown through the difference in colour coding. Consequently, Binding Theory A would be violated if the co-indexation of example 2.i) generates a strict reading. Hence, PF-deletion hypothesis generates sloppy readings because it treats the elided VP as identical structures to the antecedent VP and co-indexation is constrained by locality.
Logical Form approaches
LF-copying hypothesis
According to Carnie,[6] the sloppy identity problem can be explained using an LF-copying hypothesis. This hypothesis claims that before SPELLOUT, the elided VP has no structure and exists as an empty or null VP (as opposed to the PF-deletion hypothesis, which asserts that the elided VP has structure throughout the derivation). Only by copying structure from the VP antecedent does it have structure at LF. These copying processes occur covertly from SPELLOUT to LF.
According to LF-copying, the ambiguity found in sloppy identity is due to different orderings of the copying rules for pronouns and verbs. Consider the following derivations of the sloppy reading and the strict reading for sentence (4), using the Covert VP-Copying Rule and the Anaphor-Copying Rule:
4) Calvin will strike himself and Otto will [vp Ø] too.
Sloppy reading
In the sloppy reading, the VP-copying rule applies first, as can be seen in sentence 5). The VP-copying rule copies the VP in the antecedent into the empty VP:
Covert VP-copying rule
5) Calvin will [strike himself] and Otto will [strike himself] too.
Following the VP-copying rule, the anaphor-copying rule applies, as can be seen in sentence 6). The anaphor-copying rule, which is clause-bound, copies NPs into anaphors within the same clause:
Covert anaphor-copying rule
6) Calvin will [strike Calvin] and Otto will [strike Otto] too.
Strict reading
In the strict reading, the application of these rules occur in the opposite order. Therefore, the anaphor-copying rule is applied first. Due to the fact that the empty VP does not contain an anaphor, the NP “Otto” cannot be copied into it. This process can be seen in sentence 7):
Covert anaphor-copying rule
7) Calvin will [strike Calvin] and Otto will [vp Ø] too.
Following the anaphor-copying rule, the VP-copying rule applies and produces the sentence in 8):
Covert VP-copying rule
8) Calvin will [strike Calvin] and Otto will [strike Calvin] too.
The derivation used in this LF copying hypothesis can be found here.
Combination of PF and LF
Building on the work of Bouton (1970) and Ross (1969), Barbara Partee (1975)[3] developed what has come to be one of the most important and influential approaches to explain VP to date, the Derived VP-Rule, which introduces a null operator at the VP level. Shortly thereafter, Ivan A. Sag (1976)[1] developed the Deletion Derived VP approach, and Edwin S. Williams (1977)[5] developed the Interpretive Derived VP Approach. These rules are still used by many today.
Derived VP-rule:[3]
According to Williams [5](1977), the Derived VP Rule converts VPs in surface structure into properties written in lambda notation. This is a very important rule that has been built on over the years to make sense of sloppy identity. This VP-rule is used by many linguists as a foundation for their ellipsis rules.
Deletion-derived VP approach:[1]
Ivan Sag proposed two Logical Forms, one of which the coreferential pronoun is replaced by a bound variable.[1] This leads to the rule of semantic interpretation that takes pronouns and changes them into bound variables.[1] This rule is abbreviated as Pro→BV, where “Pro” stands for pronoun, and “BV” stands for bound variable.
Simple sentence example
9) [Betsyi loves heri dog]
The strict reading of sentence 9) is that “Betsy loves her own dog”. Application of Pro→BV then derives the sentence in 9.i):
9.i) [Betsyi loves herj(or x’s) dog]
Where herj is someone else or x’s is anyone else's dog
Complex example
10) Betsyi loves heri dog and Sandyj does ∅ too
where ∅ = loves her dog
Strict reading
The strict reading of 10) is "Betsy loves Betsy’s dog and Sandy loves Betsy’s dog as well", which implies that ∅ is a VP that has been deleted. This is represented in the following sentence:
10.i) Betsyi λx (x loves heri dog) and Sandy λy (y loves heri dog)
The VPs that are being represented by λx and λy are syntactically identical. For this reason the one that is being c-commanded (λy) can be deleted.
This then forms:
10.ii) Betsyi loves heri dog and Sandyj does ∅ too
Sloppy reading
The sloppy reading of this sentence is "Betsy loves Betsy’s dog and Sandy loves Sandy’s dog". That is, both women love their own dog. This is represented in the following sentence:
10.iii) Betsyi λx (x loves heri dog) and Sandyj λy (y loves herj dog)
Since the embedded clauses are identical, the logic of this form is that the variable x must be bound to the same noun phrase in both cases. Therefore, “Betsy” is in the commanding position that determines the interpretation of the second clause.
The Pro → BV rule that converts pronouns into bound variables can be applied to all the pronouns.
This then allows for the sentence in 10.iii) to be:
10.iv) Betsyi λx (x loves x’s dog) & Sandyj λy (y loves y’s dog)
Another way the VP can be syntactically identical is, if λx(A) and λy(B) where every instance of x in A has a corresponding instance of y in B. So, like in the example above, for all instances of x there is a corresponding instance of y and therefore they are identical and the VP that is being c-commanded can be deleted.
Step-by-step derivation
In Sag’s approach, VP Ellipsis is analyzed as a deletion that takes place in between S-structure (Shallow Structure) and PF (Surface Structure). It is claimed that the deleted VP is recoverable at the level of LF due to alphabetic variance holding between two λ-expressions.[7] In this deletion approach, the sloppy identity is made possible, first, by the indexing of anaphors, and then by the application of a variable rewriting rule.
The following is a step by step derivation, taking into consideration both Phonetic and Logical Forms, accounting for a sloppy reading of the sentence “John blamed himself, and Bill did too.”
LF mapping
Deep structure to surface structure:
11) Johni [VP blamed himself], and Billj [VP blamed himself],too.[7]
In this sentence, the VP’s [blamed himself] are present, but are not yet referencing any subject. In sentence 12), the Derived VP Rule is applied, rewriting these VP’s using lambda notation.
Derived VP Rule
12) Johni [VP λx(x blame himself)], Billj [VP λy(y blame himself)], too.[7]
The Derived VP Rule has derived two VPs containing separate λ-operators with referential variables bound in each antecedent clause. The next rule, Indexing, co-indexes Anaphors and Pronouns to their subjects.
Indexing
13) Johni[VP λx(x blame himi)], Billj [VP λy( y blame himj)], too.[7]
As we see, the anaphors have been co-indexed to their respective NPs. Lastly, The Variable Rewriting Rule replaces pronouns and anaphors with variables in Logical Form.
Pro-->BV
Logical Form:
14) Johni[VP λx(x blame x)], Billj [VP λy (y blame y)], too.[7]
PF Mapping
Deep Structure to Surface Structure:
15) John [VP blamed himself], and bill [VP blame himself], too.[7]
Here we see that both John and Bill precede the same VP, [blame himself]. It is important to note that any meaning, in this case what Subject the Anaphor “himself” references, is determined at LF, and thus left out of phonetic form.
VP-deletion
16) John [VP blamed himself], and Bill ____, too.[7]
VP Deletion occurs, which in effect deletes the VP [blame himself] from the second clause Bill [blame himeself]. Again, it is important to keep in mind that this deletion occurs strictly at the Phonetic Level, and thus [blame himself] still exists in the LF component, despite it being deleted in PF.
Do-support
Phonetic Form:
17) John [VP blamed himself], and bill did____, too.[7]
Lastly, Do-Support is implemented, filling the empty space created by VP Deletion with did. This is the last step that occurs in PF, leaving the sentence to be phonetically realized as “John blamed himself, and Bill did too.” Due to the rules enacted in the LF component of the derivation, although did has phonetically replaced the VP [blame himself], its meaning is the same as what was established at LF. Thus, “Bill did too” can be sloppily interpreted as “Bill blamed himself”, as in “Bill blamed Bill”.
Interpretative-derived VP approach
In his approach to the sloppy identity problem, Williams (1977) adopts the Derived VP Rule as well.[8] He also suggests that anaphors and pronouns are rewritten as variables at LF by a Variable Rewriting Rule. Afterwards, by using the VP Rule, these variables are then copied into the elided VP. Following this approach, both the sloppy and strict readings are possible. The following examples will go through the derivation of sentence 18.i) as a sloppy reading:
Sloppy reading
18.i) John visits his children on Sunday and Bill does [VP∅] too.[8]
As can be seen in this sentence, the VP contains no structure. In sentence 19.i), the Derived VP Rule, which re-writes the VP using lambda notation, is applied:
Derived VP Rule
19.i) John [VPλx (x visits his children)] and Bill does [VP∅] too.[8]
Next, the Variable Rewriting Rule transforms pronouns and anaphors into variables at LF:
Variable Rewriting Rule
20.i) John [VPλx (x visits x’s children)] and Bill does [VP∅] too.[8]
The VP Rule then copies the VP structure into the elided VP:
VP Rule
21.i) John [VPλx (x visits x’s children)] and Bill does [VPλx (x visits x’s children)] too.[8]
The main difference between the sloppy and the strict reading lies in the Variable Rewriting Rule. The presence of this rule allows for a sloppy reading because variables are bound by the lambda operator within the same VP. By converting the pronoun his in 20.i) into a variable, and once the VP is copied into the elided VP in sentence 21.i), the variable in the elided VP is then able to be bound by Bill. Therefore, in order to derive the strict reading, this step is simply omitted.
Strict Reading
18.ii) John visits his children on Sunday and Bill does [VP∅] too.
The VP is rewritten using lambda notation:
Derived VP Rule
19.ii) John [VPλx (x visits his children)] and Bill does [VP∅] too.
The VP structure is copied into the elided VP:
VP Rule
21.ii) John [VPλx (x visits his children)] and Bill does [VPλx (x visits his children)] too.
Due to the fact the pronoun his is already co-indexed with John, and it was not rewritten as a variable before being copied into the elided VP, there is no way for it to be bound by Bill. Therefore, the strict reading is thus derived by omitting the Variable Rewriting Rule.
Centering shift theory
The idea of ‘centering’, also known as ‘focusing’, has been discussed by numerous linguists, such as A. Joshi, S. Weinstein, and B. Grosz.[9] This theory is based on the assumption that in conversation both participants share a psychological focus towards an entity that is central to their discourse. Hardt (2003),[10] using this centering theoretical approach, suggests that in discourse, a shift of the focus from one entity to another makes it possible for sloppy readings to occur.
In the following two examples, the superscript * represents the current focus of discourse, while the subscript * signifies an entity which is in reference to the focus of discourse. Consider the following two examples:
Strict reading

22) John* scratched his* arm and Bill scratched his* arm
In the example above, there is no shift from the initial focus, thus the strict meaning arises, where both John and Bob scratched John’s arm as John is where the focus is established and remains throughout discourse. Conversely, a shift in focus away from the initial discourse focus, like in the example below, gives rise to a sloppy reading.
Sloppy Reading

23) John* scratched his* arm and Bob* scratched his* arm
Now the sloppy reading of the sentence arises, where John scratched his arm (John’s arm) and Bob scratched his arm (Bob’s arm). The shift in focus has included Bob as the primary noun and this allows the pronoun his to refer to its closest superscript *, in this case, Bob.
It must be noted that this is a simplified explanation of Centering Theory. This approach can be further explored in Hardt’s 2003[10] paper. Although beyond the scope of this discussion, Hardt’s use of Centering Theory may also explain the two pronoun ellipsis puzzle and two pronoun attitude puzzle, two puzzles which prior to Centering Theory could not be properly accounted for.
Cross-linguistic implications of sloppy identity
Instances of sloppy identity have been observed across multiple languages, however, the majority of research has centered on instances of Sloppy Identity occurring in English. Cross linguistically, Sloppy Identity is analyzed as a universal problem, found in the basic underlying syntactic structure that all languages share. For non-English examples and analyses of Sloppy Identity, such as Japanese,[11] Korean,[12] and Chinese,[13] see the following articles in the references section below.
References
- 1 2 3 4 5 6 Sag, I. A. (1976). "Deletion and Logical Form". PhD Thesis, Massachusetts Institute of Technology. New York: Garland Publishing.
- 1 2 Bouton, L (1970). "Antecedent-contained Pro Forms". Papers From the Sixth Regional Meeting of the Chicago Linguistic Society. Chicago, IL.
- 1 2 3 Partee, B (1975). "Montague grammar and transformational grammar". Linguistic Inquiry. 6 (2): 203–300.
- ↑ Chomsky, N. (1955) The logical structure of linguistic theory. Manuscript, Harvard University.
- 1 2 3 Williams, E. S. (1977). "Discourse and Logical Form". Linguistic Inquiry. 8 (1): 101–139.
- ↑ Carnie, Andrew (2013). Syntax: A generative introduction. Chichester, West Sussex: John Wiley & Sons Ltd.
- 1 2 3 4 5 6 7 8 Kitagawa, Yoshihisa (August 1991). "Copying Identity". Natural Language & Linguistic Theory. 9 (3): 497–536. doi:10.1007/bf00135356.
- 1 2 3 4 5 Lobeck, A (1995). Ellipsis: Functional heads, licensing, and identification. New York: Oxford University Press.
- ↑ Grosz, Barbara; Joshi, A.; Weinstein, S. (1995). "Centering: A framework for modeling the Local Coherence of Discourse". Computational Linguistics. 21 (2).
- 1 2 Hardt, D. (2003). "Sloppy Identity, Binding, and Centering". Proceedings from Semantics and Linguistics Theory. pp. 109–126.
- ↑ Hoji, H (1998). "Null object and Sloppy Identity in Japanese". Linguistic Inquiry. 29 (1): 127–152. doi:10.1162/002438998553680.
- ↑ Kim, S (1999). "Sloppy/Strict identity, empty objects, and NP ellipsis". journal of East Asian Linguistics. 8 (4): 255–284.
- ↑ Lust, B; F. Guo; C. Foley; Y. Chien; C. Chiang (1996). "Operator-variable binding in the initial state: A cross-linguistic study of VP ellipsis structures in Chinese and English". Cahiers de Linguistique Asie Orientale. 25 (1): 3–34.