Regularization by spectral filtering
Spectral regularization is any of a class of regularization techniques used in machine learning to control the impact of noise and prevent overfitting. Spectral regularization can be used in a broad range of applications, from deblurring images to classifying emails into a spam folder and a non-spam folder. For instance, in the email classification example, spectral regularization can be used to reduce the impact of noise and prevent overfitting when a machine learning system is being trained on a labeled set of emails to learn how to tell a spam and a non-spam email apart.
Spectral regularization algorithms rely on methods that were originally defined and studied in the theory of ill-posed inverse problems (for instance, see[1]) focusing on the inversion of a linear operator (or a matrix) that possibly has a bad condition number or an unbounded inverse. In this context, regularization amounts to substituting the original operator by a bounded operator called the "regularization operator" that has a condition number controlled by a regularization parameter,[2] a classical example being Tikhonov regularization. To ensure stability, this regularization parameter is tuned based on the level of noise.[2] The main idea behind spectral regularization is that each regularization operator can be described using spectral calculus as an appropriate filter on the eigenvalues of the operator that defines the problem, and the role of the filter is to "suppress the oscillatory behavior corresponding to small eigenvalues".[2] Therefore, each algorithm in the class of spectral regularization algorithms is defined by a suitable filter function (which needs to be derived for that particular algorithm). Three of the most commonly used regularization algorithms for which spectral filtering is well-studied are Tikhonov regularization, Landweber iteration, and truncated singular value decomposition (TSVD). As for choosing the regularization parameter, examples of candidate methods to compute this parameter include the discrepancy principle, generalized cross validation, and the L-curve criterion.[3]
It is of note that the notion of spectral filtering studied in the context of machine learning is closely connected to the literature on function approximation (in signal processing).
Notation
The training set is defined as 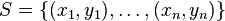 , where
, where 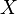 is the
is the 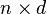 input matrix and
input matrix and 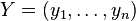 is the output vector. Where applicable, the kernel function is denoted by
is the output vector. Where applicable, the kernel function is denoted by 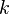 , and the
, and the 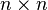 kernel matrix is denoted by
kernel matrix is denoted by 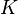 which has entries
which has entries 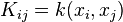 and
and 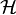 denotes the Reproducing Kernel Hilbert Space (RKHS) with kernel . The regularization parameter is denoted by
denotes the Reproducing Kernel Hilbert Space (RKHS) with kernel . The regularization parameter is denoted by 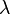 .
.
(Note: For 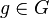 and
and 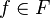 , with
, with 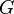 and
and 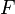 being Hilbert spaces, given a linear, continuous operator
being Hilbert spaces, given a linear, continuous operator 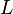 , assume that
, assume that 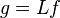 holds. In this setting, the direct problem would be to solve for
holds. In this setting, the direct problem would be to solve for 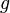 given
given 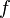 and the inverse problem would be to solve for given . If the solution exists, is unique and stable, the inverse problem (i.e. the problem of solving for ) is well-posed; otherwise, it is ill-posed.)
and the inverse problem would be to solve for given . If the solution exists, is unique and stable, the inverse problem (i.e. the problem of solving for ) is well-posed; otherwise, it is ill-posed.)
Relation to the theory of ill-posed inverse problems
The connection between the regularized least squares (RLS) estimation problem (Tikhonov regularization setting) and the theory of ill-posed inverse problems is an example of how spectral regularization algorithms are related to the theory of ill-posed inverse problems.
The RLS estimator solves
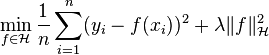
and the RKHS allows for expressing this RLS estimator as 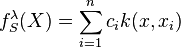 where
where 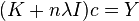 with
with 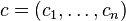 .[4] The penalization term is used for controlling smoothness and preventing overfitting. Since the solution of empirical risk minimization
.[4] The penalization term is used for controlling smoothness and preventing overfitting. Since the solution of empirical risk minimization 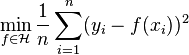 can be written as
can be written as 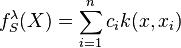 such that
such that  , adding the penalty function amounts to the following change in the system that needs to be solved:[5]
, adding the penalty function amounts to the following change in the system that needs to be solved:[5]
In this learning setting, the kernel matrix can be decomposed as  , with
, with
and 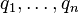 are the corresponding eigenvectors. Therefore, in the initial learning setting, the following holds:
are the corresponding eigenvectors. Therefore, in the initial learning setting, the following holds:
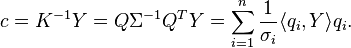
Thus, for small eigenvalues, even small perturbations in the data can lead to considerable changes in the solution. Hence, the problem is ill-conditioned, and solving this RLS problem amounts to stabilizing a possibly ill-conditioned matrix inversion problem, which is studied in the theory of ill-posed inverse problems; in both problems, a main concern is to deal with the issue of numerical stability.
Implementation of algorithms
Each algorithm in the class of spectral regularization algorithms is defined by a suitable filter function, denoted here by 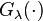 . If the Kernel matrix is denoted by , then should control the magnitude of the smaller eigenvalues of
. If the Kernel matrix is denoted by , then should control the magnitude of the smaller eigenvalues of 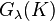 . In a filtering setup, the goal is to find estimators
. In a filtering setup, the goal is to find estimators 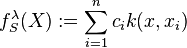 where
where 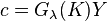 . To do so, a scalar filter function
. To do so, a scalar filter function 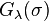 is defined using the eigen-decomposition of the kernel matrix:
is defined using the eigen-decomposition of the kernel matrix:
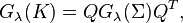
which yields
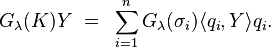
Typically, an appropriate filter function should have the following properties:[5]
1. As goes to zero, 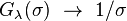 .
.
2. The magnitude of the (smaller) eigenvalues of 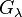 is controlled by .
is controlled by .
While the above items give a rough characterization of the general properties of filter functions for all spectral regularization algorithms, the derivation of the filter function (and hence its exact form) varies depending on the specific regularization method that spectral filtering is applied to.
Filter function for Tikhonov regularization
In the Tikhonov regularization setting, the filter function for RLS is described below. As shown in,[4] in this setting, 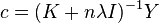 . Thus,
. Thus,
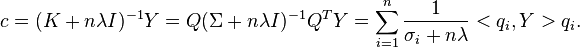
The undesired components are filtered out using regularization:
- If
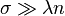 , then
, then 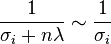 .
. - If
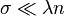 , then
, then 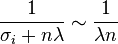 .
.
The filter function for Tikhonov regularization is therefore defined as:[5]
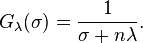
Filter function for Landweber iteration
The idea behind the Landweber iteration is gradient descent:[5]
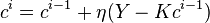
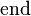
In this setting, if 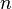 is larger than 's largest eigenvalue, the above iteration converges by choosing
is larger than 's largest eigenvalue, the above iteration converges by choosing 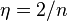 as the step-size:.[5] The above iteration is equivalent to minimizing
as the step-size:.[5] The above iteration is equivalent to minimizing 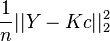 (i.e. the empirical risk) via gradient descent; using induction, it can be proved that at the
(i.e. the empirical risk) via gradient descent; using induction, it can be proved that at the 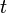 -th iteration, the solution is given by [5]
-th iteration, the solution is given by [5]
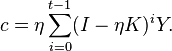
Thus, the appropriate filter function is defined by:
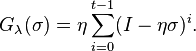
It can be shown that this filter function corresponds to a truncated power expansion of 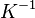 ;[5] to see this, note that the relation
;[5] to see this, note that the relation 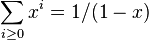 , would still hold if
, would still hold if 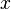 is replaced by a matrix; thus, if (the kernel matrix), or rather
is replaced by a matrix; thus, if (the kernel matrix), or rather 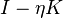 , is considered, the following holds:
, is considered, the following holds:
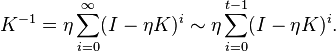
In this setting, the number of iterations gives the regularization parameter; roughly speaking, 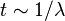 .[5] If is large, overfitting may be a concern. If is small, oversmoothing may be a concern. Thus, choosing an appropriate time for early stopping of the iterations provides a regularization effect.
.[5] If is large, overfitting may be a concern. If is small, oversmoothing may be a concern. Thus, choosing an appropriate time for early stopping of the iterations provides a regularization effect.
Filter function for TSVD
In the TSVD setting, given the eigen-decomposition and using a prescribed threshold 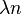 , a regularized inverse can be formed for the kernel matrix by discarding all the eigenvalues that are smaller than this threshold.[5]
Thus, the filter function for TSVD can be defined as
, a regularized inverse can be formed for the kernel matrix by discarding all the eigenvalues that are smaller than this threshold.[5]
Thus, the filter function for TSVD can be defined as
![G_\lambda(\sigma) =\left\{\begin{array}[c]{lcll}1/\sigma & ,& \text{if }\sigma\geq\lambda n\\[0.05in]0&,& \text{otherwise}\\[0.05in]\end{array}\right..](../I/m/d9410eb1982027a1ceeb36253b2b6271.png)
It can be shown that TSVD is equivalent to the (unsupervised) projection of the data using (kernel) Principal Component Analysis (PCA), and that it is also equivalent to minimizing the empirical risk on the projected data (without regularization).[5] Note that the number of components kept for the projection is the only free parameter here.
References
- ↑ H. W. Engl, M. Hanke, and A. Neubauer. Regularization of inverse problems. Kluwer, 1996.
- 1 2 3 L. Lo Gerfo, L. Rosasco, F. Odone, E. De Vito, and A. Verri. Spectral Algorithms for Supervised Learning, Neural Computation, 20(7), 2008.
- ↑ P. C. Hansen, J. G. Nagy, and D. P. O'Leary. Deblurring Images: Matrices, Spectra, and Filtering, Fundamentals of Algorithms 3, SIAM, Philadelphia, 2006.
- 1 2 L. Rosasco. Lecture 6 of the Lecture Notes for 9.520: Statistical Learning Theory and Applications. Massachusetts Institute of Technology, Fall 2013. Available at http://www.mit.edu/~9.520/fall13/slides/class06/class06_RLSSVM.pdf
- 1 2 3 4 5 6 7 8 9 10 L. Rosasco. Lecture 7 of the Lecture Notes for 9.520: Statistical Learning Theory and Applications. Massachusetts Institute of Technology, Fall 2013. Available at http://www.mit.edu/~9.520/fall13/slides/class07/class07_spectral.pdf