Learning classifier system
Learning classifier systems, or LCS, are a paradigm of rule-based machine learning methods that combine a discovery component (e.g. typically a genetic algorithm) with a learning component (performing either supervised learning, reinforcement learning, or unsupervised learning).[2] Learning classifier systems seek to identify a set of context-dependent rules that collectively store and apply knowledge in a piecewise manner in order to make predictions (e.g. behavior modeling,[3] classification,[4][5] data mining,[5][6][7] regression,[8] function approximation,[9] or game strategy). This approach allows complex solution spaces to be broken up into smaller, simpler parts.
The founding concepts behind learning classifier systems came from attempts to model complex adaptive systems, using rule-based agents to form an artificial cognitive system (i.e. artificial intelligence).
Methodology
The architecture and components of a given learning classifier system can be quite variable. It is useful to think of an LCS as a machine consisting of several interacting components. Components may be added or removed, or existing components modified/exchanged to suit the demands of a given problem domain (like algorithmic building blocks) or to make the algorithm flexible enough to function in many different problem domains. As a result, the LCS paradigm can be flexibly applied to many problem domains that call for machine learning. The major divisions among LCS implementations are as follows: (1) Michigan-style architecture vs. Pittsburgh-style architecture, (2) reinforcement learning vs. supervised learning, (3) incremental learning vs. batch learning, (4) online learning vs. offline learning, (5) strength-based fitness vs. accuracy-based fitness, and (6) complete action mapping vs best action mapping. These divisions are not necessarily mutually exclusive. For example, XCS,[10] the best known and best studied LCS algorithm, is Michigan-style, was designed for reinforcement learning but can also perform supervised learning, applies incremental learning that can be either online or offline, applies accuracy-based fitness, and seeks to generate a complete action mapping.
Elements of a generic LCS algorithm
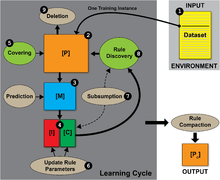
Keeping in mind that LCS is a paradigm for genetic-based machine learning rather than a specific method, the following outlines key elements of a generic, modern (i.e. post-XCS) LCS algorithm. For simplicity let us focus on Michigan-style architecture with supervised learning. See the illustrations on the right laying out the sequential steps involved in this type of generic LCS.
Environment
The environment is the source of data upon which an LCS learns. It can be an offline, finite training dataset (characteristic of a data mining, classification, or regression problem), or an online sequential stream of live training instances. Each training instance is assumed to include some number of features (also referred to as attributes, or independent variables), and a single endpoint of interest (also referred to as the class, action, phenotype, prediction, or dependent variable). Part of LCS learning can involve feature selection, therefore not all of the features in the training data need be informative. The set of feature values of an instance is commonly referred to as the state. For simplicity let's assume an example problem domain with Boolean/binary features and a Boolean/binary class. For Michigan-style systems, one instance from the environment is trained on each learning cycle (i.e. incremental learning). Pittsburgh-style systems perform batch learning, where rule-sets are evaluated each iteration over much or all of the training data.
Rule/classifier/population
A rule is a context dependent relationship between state values and some prediction. Rules typically take the form of an {IF:THEN} expression, (e.g. {IF 'condition' THEN 'action'}, or as a more specific example, {IF 'red' AND 'octagon' THEN 'stop-sign'}). A critical concept in LCS and rule-based machine learning alike, is that an individual rule is not in itself a model, since the rule is only applicable when its condition is satisfied. Think of a rule as a "local-model" of the solution space.
Rules can be represented in many different ways to handle different data types (e.g. binary, discrete-valued, ordinal, continuous-valued). Given binary data LCS traditionally applies a ternary rule representation (i.e. rules can include either a 0, 1, or '#' for each feature in the data). The 'don't care' symbol (i.e. '#') serves as a wild card within a rule's condition allowing rules, and the system as a whole to generalize relationships between features and the target endpoint to be predicted. Consider the following rule (#1###0 ~ 1) (i.e. condition ~ action). This rule can be interpreted as: IF the second feature = 1 AND the sixth feature = 0 THEN the class prediction = 1. We would say that the second and sixth features were specified in this rule, while the others were generalized. This rule, and the corresponding prediction are only applicable to an instance when the condition of the rule is satisfied by the instance. This is more commonly referred to as matching. In Michigan-style LCS, each rule has its own fitness, as well as a number of other rule-parameters associated with it that can describe the number of copies of that rule that exist (i.e. the numerosity), the age of the rule, its accuracy, or the accuracy of its reward predictions, and other descriptive or experiential statistics. A rule along with its parameters is often referred to as a classifier. In Michigan-style systems, classifiers are contained within a population [P] that has a user defined maximum number of classifiers. Unlike most stochastic search algorithms (e.g. evolutionary algorithms), LCS populations start out empty (i.e. there is no need to randomly initialize a rule population). Classifiers will instead be initially introduced to the population with a covering mechanism.
In any LCS, the trained model is a set of rules/classifiers, rather than any single rule/classifier. In Michigan-style LCS, the entire trained (and optionally, compacted) classifier population forms the prediction model.
Matching
One of the most critical and often time consuming elements of an LCS is the matching process. The first step in an LCS learning cycle takes a single training instance from the environment and passes it to [P] where matching takes place. In step two, every rule in [P] is now compared to the training instance to see which rules match (i.e. are contextually relevant to the current instance). In step three, any matching rules are moved to a match set [M]. A rule matches a training instance if all feature values specified in the rule condition are equivalent to the corresponding feature value in the training instance. For example, assuming the training instance is (001001 ~ 0), these rules would match: (###0## ~ 0), (00###1 ~ 0), (#01001 ~ 1), but these rules would not (1##### ~ 0), (000##1 ~ 0), (#0#1#0 ~ 1). Notice that in matching, the endpoint/action specified by the rule is not taken into consideration. As a result, the match set may contain classifiers that propose conflicting actions. In the fourth step, since we are performing supervised learning, [M] is divided into a correct set [C] and an incorrect set [I]. A matching rule goes into the correct set if it proposes the correct action (based on the known action of the training instance), otherwise it goes into [I]. In reinforcement learning LCS, an action set [A] would be formed here instead, since the correct action is not known.
Covering
At this point in the learning cycle, if no classifiers made it into either [M] or [C] (as would be the case when the population starts off empty), the covering mechanism is applied (fifth step). Covering is a form of online smart population initialization. Covering randomly generates a rule that matches the current training instance (and in the case of supervised learning, that rule is also generated with the correct action. Assuming the training instance is (001001 ~ 0), covering might generate any of the following rules: (#0#0## ~ 0), (001001 ~ 0), (#010## ~ 0). Covering not only ensures that each learning cycle there is at least one correct, matching rule in [C], but that any rule initialized into the population will match at least one training instance. This prevents LCS from exploring the search space of rules that do not match any training instances.
Parameter updates/credit assignment/learning
In the sixth step, the rule parameters of any rule in [M] are updated to reflect the new experience gained from the current training instance. Depending on the LCS algorithm, a number of updates can take place at this step. For supervised learning, we can simply update the accuracy/error of a rule. Rule accuracy/error is different than model accuracy/error, since it is not calculated over the entire training data, but only over all instances that it matched. Rule accuracy calculated by dividing the number of times the rule was in a correct set [C] by the number of times it was in an match set [M]. Rule accuracy can be thought of as a 'local accuracy'. Rule fitness is also updated here, and is commonly calculated as a function of rule accuracy. The concept of fitness is taken directly from classic genetic algorithms. Be aware that there are many variations on how LCS updates parameters in order to perform credit assignment and learning.
Subsumption
In the seventh step, a subsumption mechanism is typically applied. Subsumption is an explicit generalization mechanism that merges classifiers that cover redundant parts of the problem space. The subsuming classifier effectively absorbs the subsumed classifier (and has its numerosity increased). This can only happen when the subsuming classifier is more general, just as accurate, and covers all of the problem space of the classifier it subsumes.
Rule discovery/genetic algorithm
In the eighth step, LCS adopts a highly elitist genetic algorithm (GA) which will select two parent classifiers based on fitness (survival of the fittest). Parents are selected from [C] typically using tournament selection. Some systems have applied roulette wheel selection or deterministic selection, and have differently selected parent rules from either [P] - panmictic selection, or from [M]). Crossover and mutation operators are now applied to generate two new offspring rules. At this point, both the parent and offspring rules are returned to [P]. The LCS genetic algorithm is highly elitist since each learning iteration, the vast majority of the population is preserved. Rule discovery may alternatively be performed by some other method, such as an estimation of distribution algorithm, but a GA is by far the most common approach. Evolutionary algorithms like the GA employ a stochastic search, which makes LCS a stochastic algorithm. LCS seeks to cleverly explore the search space, but does not perform an exhaustive search of rule combinations, and is not guaranteed to converge on an optimal solution.
Deletion
The last step in a generic LCS learning cycle is to maintain the maximum population size. The deletion mechanism will select classifiers for deletion (commonly using roulette wheel selection). The probability of a classifier being selected for deletion is inversely proportional to its fitness. When a classifier is selected for deletion, its numerosity parameter is reduced by one. When the numerosity of a classifier is reduced to zero, it is removed entirely from the population.
Training
LCS will cycle through these steps repeatedly for some user defined number of training iterations, or until some user defined termination criteria have been met. For online learning, LCS will obtain a completely new training instance each iteration from the environment. For offline learning, LCS will iterate through a finite training dataset. Once it reaches the last instance in the dataset, it will go back to the first instance and cycle through the dataset again.
Rule compaction
Once training is complete, the rule population will inevitably contain some poor, redundant and inexperienced rules. It is common to apply a rule compaction, or condensation heuristic as a post-processing step. This resulting compacted rule population is ready to be applied as a prediction model (e.g. make predictions on testing instances), and/or to be interpreted for knowledge discovery.
Prediction
Whether or not rule compaction has been applied, the output of an LCS algorithm is a population of classifiers which can be applied to making predictions on previously unseen instances. The prediction mechanism is not part of the supervised LCS learning cycle itself, however it would play an important role in a reinforcement learning LCS learning cycle. For now we consider how the prediction mechanism can be applied for making predictions to test data. When making predictions, the LCS learning components are deactivated so that the population does not continue to learn from incoming testing data. A test instance is passed to [P] where a match set [M] is formed as usual. At this point the match set is differently passed to a prediction array. Rules in the match set can predict different actions, therefore a voting scheme is applied. In a simple voting scheme, the action with the strongest supporting 'votes' from matching rules wins, and becomes the selected prediction. All rules do not get an equal vote. Rather the strength of the vote for a single rule is commonly proportional to its numerosity and fitness. This voting scheme and the nature of how LCS's store knowledge, suggests that LCS algorithms are implicitly ensemble learners.
Interpretation
Individual LCS rules are typically human readable IF:THEN expression. Rules that constitute the LCS prediction model can be ranked by different rule parameters and manually inspected. Global strategies to guide knowledge discovery using statistical and graphical have also been proposed.[11][12] With respect to other advanced machine learning approaches, such as artificial neural networks, random forests, or genetic programming, learning classifier systems are particularly well suited to problems that require interpretable solutions.
History
Early years
John Henry Holland was best known for his work popularizing genetic algorithms (GA), through his ground-breaking book "Adaptation in Natural and Artificial Systems"[13] in 1975 and his formalization of Holland's schema theorem. In 1976, Dr. Holland conceptualized an extension of the GA concept to what he called a "cognitive system",[14] and provided the first detailed description of what would be come known as the first learning classifier system in the paper "Cognitive Systems based on Adaptive Algorithms".[15] This first system, named Cognitive System One (CS-1) was conceived as a modeling tool, designed to model a real system (i.e. environment) with unknown underlying dynamics using a population of human readable rules. The goal was for a set of rules to perform online machine learning to adapt to the environment based on infrequent payoff/reward (i.e. reinforcement learning) and apply these rules to generate a behavior that matched the real system. This early, ambitious implementation was later regarded as overly complex, yielding inconsistent results.[2][16]
Beginning in 1980, Kenneth De Jong and his student Stephen Smith took a different approach to rule-based machine learning with (LS-1), where learning was viewed as an offline optimization process rather than an online adaptation process.[17][18][19] This new approach was more similar to a standard genetic algorithm but evolved independent sets of rules. Since that time LCS methods inspired by the online learning framework introduced by Holland at the University of Michigan have been referred to as Michigan-style LCS, and those inspired by Smith and De Jong at the University of Pittsburgh have been referred to as Pittsburgh-style LCS.[2][16] In 1986, Holland developed what would be considered the standard Michigan-style LCS for the next decade.[20]
Other important concepts that emerged in the early days of LCS research included (1) the formalization of a bucket brigade algorithm (BBA) for credit assignment/learning,[21] (2) selection of parent rules from a common 'environmental niche' (i.e. the match set [M]) rather than from the whole population [P],[22] (3) covering, first introduced as a create operator,[23] (4) the formalization of an action set [A],[23] (5) a simplified algorithm architecture,[23] (6) strength-based fitness,[20] (7) consideration of single-step, or supervised learning problems[24] and the introduction of the correct set [C],[25] (8) accuracy-based fitness[26] (9) the combination of fuzzy logic with LCS[27] (which later spawned a lineage of fuzzy LCS algorithms), (10) encouraging long action chains and default hierarchies for improving performance on multi-step problems,[28][29][30] (11) examining latent learning (which later inspired a new branch of anticipatory classifier systems (ACS)[31]), and (12) the introduction of the first Q-learning-like credit assignment technique.[32] While not all of these concepts are applied in modern LCS algorithms, each were landmarks in the development of the LCS paradigm.
The revolution
Interest in learning classifier systems was reinvigorated in the mid 1990's largely due to two events; the development of the Q-Learning algorithm[33] for reinforcement learning, and the introduction of significantly simplified Michigan-style LCS architectures by Stewart Wilson.[10][34] Wilson's Zeroth-level Classifier System (ZCS)[34] focused on increasing algorithmic understandability based on Hollands standard LCS implementation.[20] This was done, in part, by removing rule-bidding and the internal message list, essential to the original BBA credit assignment, and replacing it with a hybrid BBA/Q-Learning strategy. ZCS demonstrated that a much simpler LCS architecture could perform as well as the original, more complex implementations. However, ZCS still suffered from performance drawbacks including the proliferation of over-general classifiers.
In 1995, Wilson published his landmark paper, "Classifier fitness based on accuracy" in which he introduced the classifier system XCS.[10] XCS took the simplified architecture of ZCS and added an accuracy-based fitness, a niche GA (acting in the action set [A]), an explicit generalization mechanism called subsumption, and an adaptation of the Q-Learning credit assignment. XCS was popularized by its ability to reach optimal performance while evolving accurate and maximally general classifiers as well as its impressive problem flexibility (able to perform both reinforcement learning and supervised learning) . XCS later became the best known and most studied LCS algorithm and defined a new family of accuracy-based LCS. ZCS alternatively became synonymous with strength-based LCS. XCS is also important, because it successfully bridged the gap between LCS and the field of reinforcement learning. Following the success of XCS, LCS were later described as reinforcement learning systems endowed with a generalization capability.[35] Reinforcement learning typically seeks to learn a value function that maps out a complete representation of the state/action space. Similarly, the design of XCS drives it to form an all-inclusive and accurate representation of the problem space (i.e. a complete map) rather than focusing on high payoff niches in the environment (as was the case with strength-based LCS). Conceptually, complete maps don't only capture what you should do, or what is correct, but also what you shouldn't do, or what's incorrect. Differently, most strength-based LCSs, or exclusively supervised learning LCSs seek a rule set of efficient generalizations in the form of a best action map (or a partial map). Comparisons between strength vs. accuracy-based fitness and complete vs. best action maps have since been examined in greater detail.[36][37]
In the wake of XCS
XCS inspired the development of a whole new generation of LCS algorithms and applications. In 1995, Congdon was the first to apply LCS to real-world epidemiological investigations of disease [38] followed closely by Holmes who developed the BOOLE++,[39] EpiCS,[40] and later EpiXCS[41] for epidemiological classification. These early works inspired later interest in applying LCS algorithms to complex and large-scale data mining tasks epitomized by bioinformatics applications. In 1998, Stolzmann introduced anticipatory classifier systems (ACS) which included rules in the form of 'condition-action-effect, rather than the classic 'condition-action' representation.[31] ACS was designed to predict the perceptual consequences of an action in all possible situations in an environment. In other words, the system evolves a model that specifies not only what to do in a given situation, but also provides information of what will happen after a specific action will be executed. This family of LCS algorithms is best suited to multi-step problems, planning, speeding up learning, or disambiguating perceptual aliasing (i.e. where the same observation is obtained in distinct states but requires different actions). Butz later pursued this anticipatory family of LCS developing a number of improvements to the original method.[42] In 2002, Wilson introduced XCSF, adding a computed action in order to perform function approximation.[43] In 2003, Bernado-Mansilla introduced a sUpervised Classifier System (UCS), which specialized the XCS algorithm to the task of supervised learning, single-step problems, and forming a best action set. UCS removed the reinforcement learning strategy in favor of a simple, accuracy-based rule fitness as well as the explore/exploit learning phases, characteristic of many reinforcement learners. Bull introduced a simple accuracy-based LCS (YCS)[44] and a simple strength-based LCS Minimal Classifier System (MCS)[45] in order to develop a better theoretical understanding of the LCS framework. Bacardit introduced GAssist[46] and BioHEL,[47] Pittsburgh-style LCSs designed for data mining and scalability to large datasets in bioinformatics applications. In 2008, Drugowitsch published the book titled "Design and Analysis of Learning Classifier Systems" including some theoretical examination of LCS algorithms.[48] Butz introduced the first rule online learning visualization within a GUI for XCSF[1] (see the image at the top of this page). Urbanowicz extended the UCS framework and introduced ExSTraCS, explicitly designed for supervised learning in noisy problem domains (e.g. epidemiology and bioinformatics).[49] ExSTraCS integrated (1) expert knowledge to drive covering and genetic algorithm towards important features in the data,[50] (2) a form of long-term memory referred to as attribute tracking,[51] allowing for more efficient learning and the characterization of heterogeneous data patterns, and (3) a flexible rule representation similar to Bacardit's mixed discrete-continuous attribute list representation.[52] Both Bacardit and Urbanowicz explored statistical and visualization strategies to interpret LCS rules and perform knowledge discovery for data mining.[11][12] Browne and Iqbal explored the concept of reusing building blocks in the form of code fragments and cyclic graphs and were the first to solve the 135-bit mulitplexer benchmark problem by first learning useful building blocks from simpler multiplexer problems.[53] ExSTraCS 2.0 was later introduced to improve Michigan-style LCS scalability, successfully solving the 135-bit multiplexer benchmark problem for the first time directly.[5] The n-bit multiplexer problem is highly epistatic and heterogeneous, making it a very challenging machine learning task.
Variants
Michigan-Style Learning Classifier System
Michigan-Style LCSs are characterized by a population of rules where the genetic algorithm operates at the level of individual rules and the solution is represented by the entire rule population. Michigan style systems also learn incrementally which allows them to perform both reinforcement learning and supervised learning, as well as both online and offline learning. Michigan-style systems have the advantage of being applicable to a greater number of problem domains, and the unique benefits of incremental learning.
Pittsburgh-Style Learning Classifier System
Pittsburgh-Style LCSs are characterized by a population of variable length rule-sets where each rule-set is a potential solution. The genetic algorithm typically operates the level of an entire rule-set. Pittsburgh-style systems also can uniquely evolved ordered rule lists, as well as employ a default rule. These systems have the natural advantage of identifying smaller rule sets, making these systems more interpretable with regards to manual rule inspection.
Hybrid systems
Systems that seek to combine key strengths of both systems have also been proposed.
Advantages
- Adaptive: They can acclimate to a changing environment in the case of online learning.
- Model free: They make limited assumptions about the environment, or the patterns of association within the data.
- The can model complex, epistatic, heterogeneous, or distributed underlying patterns without relying on prior knowledge.
- They make no assumptions about the number of predictive vs. non-predictive features in the data.
- Ensemble Learner: No single model is applied to a given instance that universally provides a prediction. Instead a relevant and often conflicting set of rules contribute a 'vote' which can be interpreted as a fuzzy prediction.
- Stochastic Learner: Non-deterministic learning is advantageous in large-scale or high complexity problems where deterministic or exhaustive learning becomes intractable.
- Implicitly Multi-objective: Rules evolve towards accuracy with implicit and explicit pressures encouraging maximal generality/simplicity. This implicit generalization pressure is unique to LCS. Effectively, more general rules, will appear more often in match sets. In turn, they have a more frequent opportunity to be selected as parents, and pass on their more general (genomes) to offspring rules.
- Interpretable:In the interest of data mining and knowledge discovery individual LCS rules are logical, human interpretable IF:THEN statements. Effective strategies have also been introduced to allow for global knowledge discovery identifying significant features, and patterns of association from the rule population as a whole.[11]
- Flexible application
- Single or multi-step problems
- Supervised, Reinforcement or Unsupervised Learning
- Binary Class and Multi-Class Classification
- Regression
- Discrete or continuous features (or some mix of both types)
- Clean or noisy problem domains
- Balanced or imbalanced datasets.
- Accommodates missing data (i.e. missing feature values in training instances)
Disadvantages
- Limited Software Availability: There are a limited number of open source, accessible LCS implementations, and even fewer that are designed to be user friendly or accessible to machine learning practitioners.
- Interpretation: While LCS algorithms are certainly more interpretable than some advanced machine learners, users must interpret a set of rules (sometimes large sets of rules to comprehend the LCS model. Methods for rule compaction, and interpretation strategies remains an area of active research.
- Theory/Convergence Proofs: There is a relatively small body of theoretical work behind LCS algorithms. This is likely due to their relative algorithmic complexity (applying a number of interacting components) as well as their stochastic nature.
- Overfitting: Like any machine learner, LCS can suffer from overfitting despite implicit and explicit generalization pressures.
- Run Parameters: LCSs often have many run parameters to consider/optimize. Typically, most parameters can be left to the community determined defaults with the exception of two critical parameters: Maximum rule population size, and the maximum number of learning iterations. Optimizing these parameters are likely to be very problem dependent.
- Notoriety: Despite their age, LCS algorithms are still not widely known even in machine learning communities. As a result, LCS algorithms are rarely considered in comparison to other established machine learning approaches. This is likely due to the following factors: (1) LCS is a relatively complicated algorithmic approach, (2) LCS, rule-based modeling is a different paradigm of modeling than almost all other machine learning approaches. (3) LCS software implementations are not as common.
- Computationally Expensive: While certainly more feasible than some exhaustive approaches, LCS algorithms can be computationally expensive. For simple, linear learning problems there is no need to apply an LCS. LCS algorithms are best suited to complex problem spaces, or problem spaces in which little prior knowledge exists.
Problem domains
- Adaptive-control
- Data Mining
- Engineering Design
- Feature Selection
- Function Approximation
- Game-Play
- Image Classification
- Knowledge Handeling
- Medical Diagnosis
- Modeling
- Navigation
- Optimization
- Prediction
- Querying
- Robotics
- Routing
- Rule-Induction
- Scheduling
- Strategy
Terminology
The name, "Learning Classifier System (LCS)", is a bit misleading since there are many machine learning algorithms that 'learn to classify' (e.g. decision trees, artificial neural networks), but are not LCSs. The term 'rule-based machine learning (RBML)' is useful, as it more clearly captures the essential 'rule-based' component of these systems, but it also generalizes to methods that are not considered to be LCSs (e.g. association rule learning, or artificial immune systems). More general terms such as, 'genetics-based machine learning', and even 'genetic algorithm'[38] have also been applied to refer to what would be more characteristically defined as a learning classifier system. Due to their similarity to genetic algorithms, Pittsburgh-style learning classifier systems are sometimes generically referred to as 'genetic algorithms'. Beyond this, some LCS algorithms, or closely related methods, have been referred to as 'cognitive systems',[15] 'adaptive agents', 'production systems', or generically as a 'classifier system'.[54][55] This variation in terminology contributes to some confusion in the field.
Up until the 2000's nearly all learning classifier system methods were developed with reinforcement learning problems in mind. As a result, the term ‘learning classifier system’ was commonly defined as the combination of ‘trial-and-error’ reinforcement learning with the global search of a genetic algorithm. Interest in supervised learning applications, and even unsupervised learning have since broadened the use and definition of this term.
See also
- Rule-based machine learning
- Production system
- Expert system
- Genetic algorithm
- Association rule learning
- Artificial immune system
- Population-based Incremental Learning
- Machine learning
References
- 1 2 Stalph, Patrick O.; Butz, Martin V. (2010-02-01). "JavaXCSF: The XCSF Learning Classifier System in Java". SIGEVOlution. 4 (3): 16–19. doi:10.1145/1731888.1731890. ISSN 1931-8499.
- 1 2 3 Urbanowicz, Ryan J.; Moore, Jason H. (2009-09-22). "Learning Classifier Systems: A Complete Introduction, Review, and Roadmap". Journal of Artificial Evolution and Applications. 2009: 1–25. doi:10.1155/2009/736398. ISSN 1687-6229.
- ↑ Dorigo, Marco. "Alecsys and the AutonoMouse: Learning to control a real robot by distributed classifier systems". Machine Learning. 19 (3): 209–240. doi:10.1007/BF00996270. ISSN 0885-6125.
- ↑ Bernadó-Mansilla, Ester; Garrell-Guiu, Josep M. (2003-09-01). "Accuracy-Based Learning Classifier Systems: Models, Analysis and Applications to Classification Tasks". Evolutionary Computation. 11 (3): 209–238. doi:10.1162/106365603322365289. ISSN 1063-6560.
- 1 2 3 Urbanowicz, Ryan J.; Moore, Jason H. (2015-04-03). "ExSTraCS 2.0: description and evaluation of a scalable learning classifier system". Evolutionary Intelligence. 8 (2-3): 89–116. doi:10.1007/s12065-015-0128-8. ISSN 1864-5909. PMC 4583133
 . PMID 26417393.
. PMID 26417393. - ↑ Bernadó, Ester; Llorà, Xavier; Garrell, Josep M. (2001-07-07). Lanzi, Pier Luca; Stolzmann, Wolfgang; Wilson, Stewart W., eds. Advances in Learning Classifier Systems. Lecture Notes in Computer Science. Springer Berlin Heidelberg. pp. 115–132. doi:10.1007/3-540-48104-4_8. ISBN 9783540437932.
- ↑ Bacardit, Jaume; Butz, Martin V. (2007-01-01). Kovacs, Tim; Llorà, Xavier; Takadama, Keiki; Lanzi, Pier Luca; Stolzmann, Wolfgang; Wilson, Stewart W., eds. Learning Classifier Systems. Lecture Notes in Computer Science. Springer Berlin Heidelberg. pp. 282–290. doi:10.1007/978-3-540-71231-2_19. ISBN 9783540712305.
- ↑ Urbanowicz, Ryan; Ramanand, Niranjan; Moore, Jason (2015-01-01). "Continuous Endpoint Data Mining with ExSTraCS: A Supervised Learning Classifier System". Proceedings of the Companion Publication of the 2015 Annual Conference on Genetic and Evolutionary Computation. GECCO Companion '15. New York, NY, USA: ACM: 1029–1036. doi:10.1145/2739482.2768453. ISBN 9781450334884.
- ↑ Butz, M. V.; Lanzi, P. L.; Wilson, S. W. (2008-06-01). "Function Approximation With XCS: Hyperellipsoidal Conditions, Recursive Least Squares, and Compaction". IEEE Transactions on Evolutionary Computation. 12 (3): 355–376. doi:10.1109/TEVC.2007.903551. ISSN 1089-778X.
- 1 2 3 Wilson, Stewart W. (1995-06-01). "Classifier Fitness Based on Accuracy". Evol. Comput. 3 (2): 149–175. doi:10.1162/evco.1995.3.2.149. ISSN 1063-6560.
- 1 2 3 Urbanowicz, R. J.; Granizo-Mackenzie, A.; Moore, J. H. (2012-11-01). "An analysis pipeline with statistical and visualization-guided knowledge discovery for Michigan-style learning classifier systems". IEEE Computational Intelligence Magazine. 7 (4): 35–45. doi:10.1109/MCI.2012.2215124. ISSN 1556-603X. PMC 4244006. PMID 25431544.
- 1 2 Bacardit, Jaume, and Xavier Llorà. "Large‐scale data mining using genetics‐based machine learning." Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 3, no. 1 (2013): 37-61.
- ↑ Holland, John (1975). Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. Michigan Press.
- ↑ Holland JH (1976) Adaptation. In: Rosen R, Snell F (eds) Progress in theoretical biology, vol 4. Academic Press, New York, pp 263–293
- 1 2 Holland JH, Reitman JS (1978) Cognitive systems based on adaptive algorithms Reprinted in: Evolutionary computation. The fossil record. In: David BF (ed) IEEE Press, New York 1998. ISBN 0-7803-3481-7
- 1 2 Lanzi, Pier Luca (2008-02-08). "Learning classifier systems: then and now". Evolutionary Intelligence. 1 (1): 63–82. doi:10.1007/s12065-007-0003-3. ISSN 1864-5909.
- ↑ Smith S (1980) A learning system based on genetic adaptive algorithms. Ph.D. thesis, Department of Computer Science, University of Pittsburgh
- ↑ Smith S (1983) Flexible learning of problem solving heuristics through adaptive search. In: Eighth international joint conference on articial intelligence. Morgan Kaufmann, Los Altos, pp 421–425
- ↑ De Jong KA (1988) Learning with genetic algorithms: an overview. Mach Learn 3:121–138
- 1 2 3 Holland, John H. "Escaping brittleness: the possibilities of general purpose learning algorithms applied to parallel rule-based system." Machine learning(1986): 593-623.
- ↑ Holland, John H. (1985-01-01). "Properties of the Bucket Brigade". Proceedings of the 1st International Conference on Genetic Algorithms. Hillsdale, NJ, USA: L. Erlbaum Associates Inc.: 1–7. ISBN 0805804269.
- ↑ Booker, L (1982-01-01). Intelligent Behavior as a Adaptation to the Task Environment (Thesis). University of Michigan.
- 1 2 3 Wilson, S. W. "Knowledge growth in an artificial animal. Proceedings of the First International Conference on Genetic Algorithms and their Applications." (1985).
- ↑ Wilson, Stewart W. "Classifier systems and the animat problem". Machine Learning. 2 (3): 199–228. doi:10.1007/BF00058679. ISSN 0885-6125.
- ↑ Bonelli, Pierre; Parodi, Alexandre; Sen, Sandip; Wilson, Stewart (1990-01-01). "NEWBOOLE: A Fast GBML System". Proceedings of the Seventh International Conference (1990) on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.: 153–159. ISBN 1558601414.
- ↑ Frey, Peter W.; Slate, David J. "Letter recognition using Holland-style adaptive classifiers". Machine Learning. 6 (2): 161–182. doi:10.1007/BF00114162. ISSN 0885-6125.
- ↑ Valenzuela-Rendón, Manuel. "The Fuzzy Classifier System: A Classifier System for Continuously Varying Variables." In ICGA, pp. 346-353. 1991.
- ↑ Riolo, Rick L. (1988-01-01). Empirical Studies of Default Hierarchies and Sequences of Rules in Learning Classifier Systems (Thesis). Ann Arbor, MI, USA: University of Michigan.
- ↑ R.L., Riolo, (1987-01-01). "Bucket brigade performance. I. Long sequences of classifiers". Genetic algorithms and their applications : proceedings of the second International Conference on Genetic Algorithms : July 28–31, 1987 at the Massachusetts Institute of Technology, Cambridge, MA.
- ↑ R.L., Riolo, (1987-01-01). "Bucket brigade performance. II. Default hierarchies". Genetic algorithms and their applications : proceedings of the second International Conference on Genetic Algorithms : July 28–31, 1987 at the Massachusetts Institute of Technology, Cambridge, MA.
- 1 2 W. Stolzmann, "Anticipatory classifier systems," in Proceedings of the 3rd Annual Genetic Programming Conference, pp. 658–664, 1998.
- ↑ Riolo, Rick L. (1990-01-01). "Lookahead Planning and Latent Learning in a Classifier System". Proceedings of the First International Conference on Simulation of Adaptive Behavior on From Animals to Animats. Cambridge, MA, USA: MIT Press: 316–326. ISBN 0262631385.
- ↑ Watkins, Christopher John Cornish Hellaby. "Learning from delayed rewards." PhD diss., University of Cambridge, 1989.
- 1 2 Wilson, Stewart W. (1994-03-01). "ZCS: A Zeroth Level Classifier System". Evolutionary Computation. 2 (1): 1–18. doi:10.1162/evco.1994.2.1.1. ISSN 1063-6560.
- ↑ Lanzi, P. L. "Learning classifier systems from a reinforcement learning perspective". Soft Computing. 6 (3-4): 162–170. doi:10.1007/s005000100113. ISSN 1432-7643.
- ↑ Kovacs, Timothy Michael Douglas. A Comparison of Strength and Accuracy-based Fitness in Learning and Classifier Systems. 2002.
- ↑ Kovacs, Tim. "Two views of classifier systems." In International Workshop on Learning Classifier Systems, pp. 74-87. Springer Berlin Heidelberg, 2001
- 1 2 Congdon, Clare Bates. "A comparison of genetic algorithms and other machine learning systems on a complex classification task from common disease research." PhD diss., The University of Michigan, 1995.
- ↑ Holmes, John H. (1996-01-01). "A Genetics-Based Machine Learning Approach to Knowledge Discovery in Clinical Data". Proceedings of the AMIA Annual Fall Symposium: 883. ISSN 1091-8280. PMC 2233061.
- ↑ Holmes, John H. "Discovering Risk of Disease with a Learning Classifier System." In ICGA, pp. 426-433. 1997.
- ↑ Holmes, John H., and Jennifer A. Sager. "Rule discovery in epidemiologic surveillance data using EpiXCS: an evolutionary computation approach." InConference on Artificial Intelligence in Medicine in Europe, pp. 444-452. Springer Berlin Heidelberg, 2005.
- ↑ Butz, Martin V. "Biasing exploration in an anticipatory learning classifier system." In International Workshop on Learning Classifier Systems, pp. 3-22. Springer Berlin Heidelberg, 2001.
- ↑ Wilson, Stewart W. "Classifiers that approximate functions". Natural Computing. 1 (2-3): 211–234. doi:10.1023/A:1016535925043. ISSN 1567-7818.
- ↑ Bull, Larry. "A simple accuracy-based learning classifier system." Learning Classifier Systems Group Technical Report UWELCSG03-005, University of the West of England, Bristol, UK (2003).
- ↑ Bull, Larry. "A simple payoff-based learning classifier system." InInternational Conference on Parallel Problem Solving from Nature, pp. 1032-1041. Springer Berlin Heidelberg, 2004.
- ↑ Peñarroya, Jaume Bacardit. "Pittsburgh genetic-based machine learning in the data mining era: representations, generalization, and run-time." PhD diss., Universitat Ramon Llull, 2004.
- ↑ Bacardit, Jaume; Burke, Edmund K.; Krasnogor, Natalio (2008-12-12). "Improving the scalability of rule-based evolutionary learning". Memetic Computing. 1 (1): 55–67. doi:10.1007/s12293-008-0005-4. ISSN 1865-9284.
- ↑ Design and Analysis of Learning Classifier Systems - Springer. doi:10.1007/978-3-540-79866-8.
- ↑ Urbanowicz, Ryan J., Gediminas Bertasius, and Jason H. Moore. "An extended michigan-style learning classifier system for flexible supervised learning, classification, and data mining." In International Conference on Parallel Problem Solving from Nature, pp. 211-221. Springer International Publishing, 2014.
- ↑ Urbanowicz, Ryan J., Delaney Granizo-Mackenzie, and Jason H. Moore. "Using expert knowledge to guide covering and mutation in a michigan style learning classifier system to detect epistasis and heterogeneity." InInternational Conference on Parallel Problem Solving from Nature, pp. 266-275. Springer Berlin Heidelberg, 2012.
- ↑ Urbanowicz, Ryan; Granizo-Mackenzie, Ambrose; Moore, Jason (2012-01-01). "Instance-linked Attribute Tracking and Feedback for Michigan-style Supervised Learning Classifier Systems". Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation. GECCO '12. New York, NY, USA: ACM: 927–934. doi:10.1145/2330163.2330291. ISBN 9781450311779.
- ↑ Bacardit, Jaume; Krasnogor, Natalio (2009-01-01). "A Mixed Discrete-continuous Attribute List Representation for Large Scale Classification Domains". Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation. GECCO '09. New York, NY, USA: ACM: 1155–1162. doi:10.1145/1569901.1570057. ISBN 9781605583259.
- ↑ Iqbal, Muhammad; Browne, Will N.; Zhang, Mengjie (2013-01-01). "Extending Learning Classifier System with Cyclic Graphs for Scalability on Complex, Large-scale Boolean Problems". Proceedings of the 15th Annual Conference on Genetic and Evolutionary Computation. GECCO '13. New York, NY, USA: ACM: 1045–1052. doi:10.1145/2463372.2463500. ISBN 9781450319638.
- ↑ Booker, L. B.; Goldberg, D. E.; Holland, J. H. (1989-09-01). "Classifier systems and genetic algorithms". Artificial Intelligence. 40 (1): 235–282. doi:10.1016/0004-3702(89)90050-7.
- ↑ Wilson, Stewart W., and David E. Goldberg. "A critical review of classifier systems." In Proceedings of the third international conference on Genetic algorithms, pp. 244-255. Morgan Kaufmann Publishers Inc., 1989.
External links
Video tutorial
- Learning Classifier Systems in a Nutshell - (2016) Go inside a basic LCS algorithm to learn their components and how they work.