Hunt–McIlroy algorithm
In computer science, the Hunt–McIlroy algorithm is a solution to the longest common subsequence problem. It was one of the first non-heuristic algorithms used in diff. To this day, variations of this algorithm are found in incremental version control systems, wiki engines, and molecular phylogenetics research software.
The research accompanying the final version of Unix diff, written by Douglas McIlroy, was published in the 1976 paper "An Algorithm for Differential File Comparison", co-written with James W. Hunt, who developed an initial prototype of diff.[1]
Algorithm
The Hunt–McIlroy algorithm is a modification to a basic solution for the longest common subsequence problem. The solution is modified so that there are lower time and space requirements for the algorithm when it is working with typical inputs.
Basic Longest Common Subsequence Solution
Algorithm
Let Ai be the ith line of the first file.
Let Bj be the jth line of the second file.
Let Pij be the length of the longest common subsequence for the first i lines of the first file and the first j lines of the second file.

Example

Consider the files A and B.
A contains three lines:
- A1 = a
- A2 = b
- A3 = c
B contains three lines:
- B1 = a
- B2 = c
- B3 = b
The steps the above algorithm would perform to determine the length of the longest common subsequence for both files are shown in the diagram. The algorithm correctly reports that the longest common subsequence of the two files is two lines long.
Complexity
The above algorithm has worst-case time and space complexities of (see big O notation), where m is the number of lines in file A and n is the number of lines in file B. The Hunt–McIlroy algorithm modifies this algorithm to have a worst case time complexity of and space complexity of , though it regularly beats the worst-case with typical inputs.


Essential Matches
k-candidates
The Hunt–McIlroy algorithm only considers what the authors call essential matches, or k-candidates. k-candidates are pairs of indices (i, j) such that:
- Ai = Bj
- Pij > max(Pi-1, j, Pi, j-1)
The second point implies two properties of k-candidates:
- There is a common subsequence of length k in the first i lines of file A and the first j lines of file B.
- There are no common subsequences of length k for any fewer than i lines of file A or j lines of file B.
Connecting k-candidates
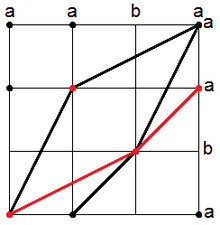
To create the longest common subsequence from a collection of k-candidates, a grid with each file's contents on each axis is created. The k-candidates are marked on the grid. A common subsequence can be created by joining marked coordinates of the grid such that any increase in i is accompanied by an increase in j.
This is illustrated in the adjacent diagram.
Black dots represent candidates that would have to be considered by the simple algorithm and the black lines are connections that create common subsequences of length 3.
Red dots represent k-candidates that are considered by the Hunt–McIlroy algorithm and the red line is the connection that creates a common subsequence of length 3.
See also
References
- ↑ Hunt, James W.; McIlroy, M. Douglas (June 1976). "An Algorithm for Differential File Comparison" (PDF). Computing Science Technical Report. Bell Laboratories. 41.