Heaps' law
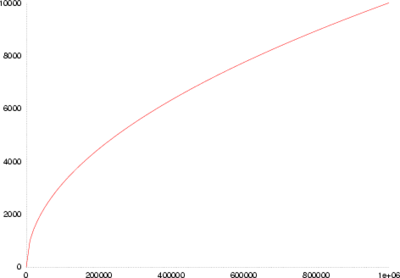
In linguistics, Heaps' law (also called Herdan's law) is an empirical law which describes the number of distinct words in a document (or set of documents) as a function of the document length (so called type-token relation). It can be formulated as

where VR is the number of distinct words in an instance text of size n. K and β are free parameters determined empirically. With English text corpora, typically K is between 10 and 100, and β is between 0.4 and 0.6.
The law is frequently attributed to Harold Stanley Heaps, but was originally discovered by Gustav Herdan (1960).[1] Under mild assumptions, the Herdan–Heaps law is asymptotically equivalent to Zipf's law concerning the frequencies of individual words within a text.[2] This is a consequence of the fact that the type-token relation (in general) of a homogenous text can be derived from the distribution of its types.[3]
Heaps' law means that as more instance text is gathered, there will be diminishing returns in terms of discovery of the full vocabulary from which the distinct terms are drawn.
Heaps' law also applies to situations in which the "vocabulary" is just some set of distinct types which are attributes of some collection of objects. For example, the objects could be people, and the types could be country of origin of the person. If persons are selected randomly (that is, we are not selecting based on country of origin), then Heaps' law says we will quickly have representatives from most countries (in proportion to their population) but it will become increasingly difficult to cover the entire set of countries by continuing this method of sampling.
Notes
- ↑ Egghe (2007): "Herdan's law in linguistics and Heaps' law in information retrieval are different formulations of the same phenomenon".
- ↑ Kornai (1999); Baeaza-Yates & Navarro (2000); van Leijenhorst & van der Weide (2003).
- ↑ Milička (2009)
References
- Baeza-Yates, Ricardo; Navarro, Gonzalo, "Block addressing indices for approximate text retrieval", Journal of the American Society for Information Science, 51 (1): 69–82, doi:10.1002/(sici)1097-4571(2000)51:1<69::aid-asi10>3.0.co;2-c.
- Egghe, L. (2007), "Untangling Herdan's law and Heaps' law: Mathematical and informetric arguments", Journal of the American Society for Information Science and Technology, 58 (5): 702, doi:10.1002/asi.20524.
- Heaps, Harold Stanley (1978), Information Retrieval: Computational and Theoretical Aspects, Academic Press. Heaps' law is proposed in Section 7.5 (pp. 206–208).
- Herdan, Gustav (1960), Type-token mathematics, The Hague: Mouton.
- Kornai, Andras (1999), "Zipf's law outside the middle range", in Rogers, James, Proceedings of the Sixth Meeting on Mathematics of Language, University of Central Florida, pp. 347–356.
- Milička, Jiří (2009), "Type-token & Hapax-token Relation: A Combinatorial Model", Glottotheory. International Journal of Theoretical Linguistics, 1 (2): 99–110, doi:10.1515/glot-2009-0009.
- van Leijenhorst, D. C; van der Weide, Th. P. (2005), "A formal derivation of Heaps' Law", Information Sciences, 170 (2–4): 263–272, doi:10.1016/j.ins.2004.03.006.
This article incorporates material from Heaps' law on PlanetMath, which is licensed under the Creative Commons Attribution/Share-Alike License.